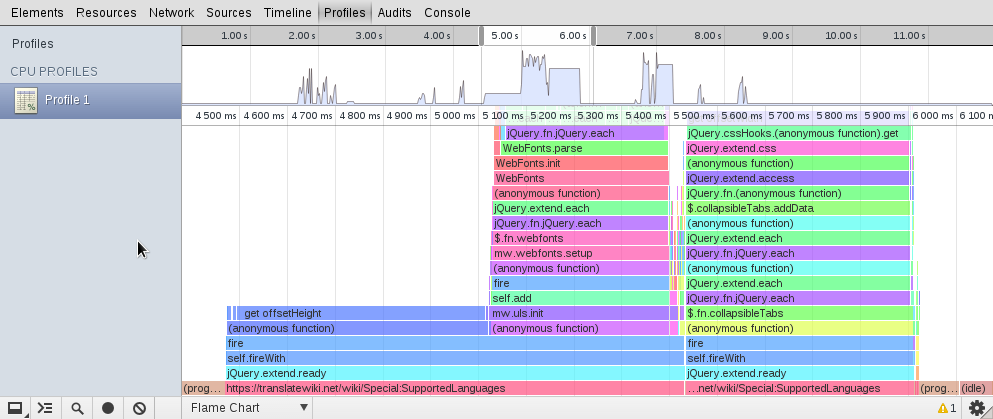
It’s been a busy while since last update, but how could I have not worked on translatewiki.net? ;) Here is an update on my current activities.
In this episode:
- we provide translations for over 70 % of users of the new Wikipedia app,
- I read a book on networking performance and get needy for speed,
- ElasticSearch tries to eat all of us and our memory,
- HHVM finds the place not fancy enough,
- Finns and Swedes start cooperating.
Performance
Naturally, I have been thinking of ways to further improve translatewiki.net performance. I have been running HHVM as a beta feature at translatewiki.net many months now, but I have kept turning it on and off due to stability issues. It is currently disabled, but my plan is to try the Wikimedia packaged version of HHVM. Those packages only work in Ubuntu 2014.04, so Siebrand and I first have to upgrade the translatewiki.net server from Ubuntu 2012.04, as we plan to later this month (July). (Update: done as of 2014-07-09, 14 UTC.)
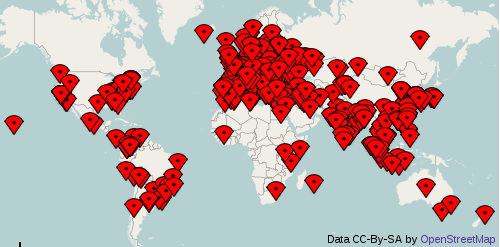
A global network of translators is not served well enough from a single location
After reading a book about networking performance I finally decided to give a content distribution network (CDN) a try. Not because they can optimize and cache things on the fly [1], nor because the can do spam protection [2], but because CDN can reduce latency, which is usually the main bottleneck of web browsing. We only have single server in Germany, but our users are international. I am close to the server, so I have much better experience than many of our users. I do not have any numbers yet, but I will do some experiments and gather some numbers to see whether CDN helps us.
[1] MediaWiki is already very aggressive in terms of optimizations for resource delivery.
[2] Restricting account creation already eliminated spam on our wiki.
Wikimedia Mobile Apps
Amir and I have been closely working with the Wikimedia Mobile Apps team to ensure that their apps are well supported. In just a couple weeks, the new app was translated in dozens languages and released, with over 7 millions new installations by non-English users (74 % of the total).
In more detail, we finally addressed a longstanding issue in the Android app which prevented translation of strings containing links. I gave Yuvi access to synchronize translations, ensuring that translators have as much time as possible to translate and the apps have the latest updates before being released. We also discussed about how to notify translators before releases to get more translations in time, and about improvements to their i18n frameworks to bring their flexibility more in line with MediaWiki (including plural support).
To put it bluntly, for some reason the mobile i18n frameworks are ugly and hard to work with. Just as an example, Android did not support many languages at all just for one character too much; support is still partial. I can’t avoid comparing this to the extra effort which has been needed to support old versions of Internet Explorer: we would rather be doing other cool things, but the environment is not going to change anytime soon.
Search
I installed and enabled CirrusSearch on translatewiki.net: for the first time, we have a real search engine for all our pages! I had multiple issues, including running a bit tight on memory while indexing all content.
Translate’s translation memory support for ElasticSearch has been almost ready for a while now. It may take a couple months before we’re ready to migrate from Solr (first on translatewiki.net, then Wikimedia sites). I am looking forward to it: as a system administrator, I do not want to run both Solr and ElasticSearch.
I want to say big thanks to Nik for helping both with the translation memory ElasticSearch backend and my CirrusSearch problems.
Wikimedia Sweden launches a new project
I am expecting to see an increased activity and new features at translatewiki.net thanks to a new project by Wikimedia Sweden together with InternetFonden.Se. The project has been announced on the Wikimedia blog, but in short they want to bring more Swedish translators, new projects for translation and possibly open badges to increase translator engagement. They are already looking for feedback, please do share your thoughts.