Long time no post! Let’s fix that with another report from my travels. This one is mostly about work.
Wikimedia hackathon was held in Vienna in May 2017. It is an event many MediaWiki developers come to meet and work together on various kinds of things – the more experiences developers helping the newcomers. For me this was one of the best events of this kind which I have attended because it was very well organized and I had a good balance between working on things and helping others.
The main theme for me for this hackathon was translatewiki.net. This was great, because recently I have not had as much time to work on improving translatewiki.net as I used to. But this does not mean there hasn’t been any, I just haven’t made any noise about it. For example, we have greatly increased automation for importing and exporting translations, new projects are being added, the operating systems have been updates, and so on. But let’s talk about what happened during the hackathon.
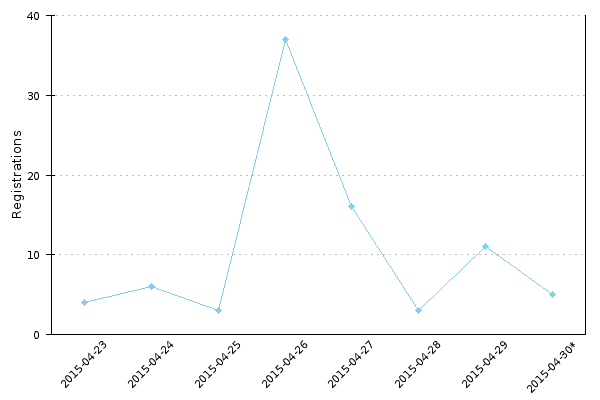
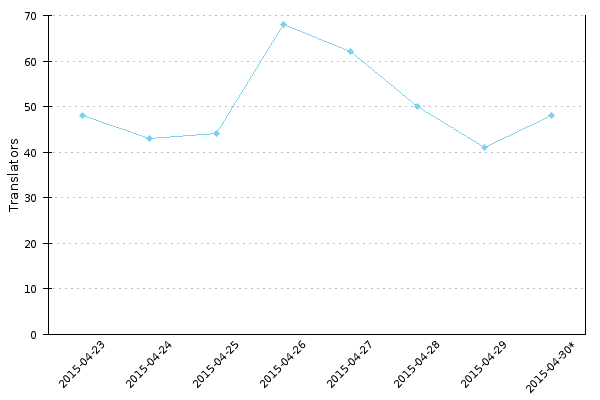
I worked with with Nemo_bis and Siebrand (they did most of the work) to go over backlog of support requests from translatewiki.net. We addressed more than half of 101 open support requests, also by adding support for 7 locales. Relatedly, we also helped a couple of people to start translating at translatewiki.net or to contribute to CLDR language database for their language.
Siebrand and I held an open post-mortem (anyone could join) about a 25 hours downtime that happened to translatewiki.net just before the event. There we reflected how we handled the situation, and how we could we do better in the future. The main take-aways are better communication (twitter, status page), server upgrade and using it for increased redundancy and periodically doing restoration practices to ensure we can restore quickly if the need arises.
Amir revived his old project that allows translating messages using a chat application (the prototype uses Telegram). Many people (at least Amir, Taras, Mt.Du and I) worked on different aspects on that project. I installed the MediaWiki OAuth extension (without which it would not be possible to do the translations using the correct user name) to translatewiki.net, and gave over-the-shoulder help for the coders.

Hackathon attendees working on their computers. Photo CC-BY-SA 3.0 by Nemo_bis
As always, some bugs were found and fixed during the hackathon. I fixed an issue in Translate where the machine translation suggestions using the Apertium service hosted by Wikimedia Foundation were not showing up. I also reported an issue with our discussion extension (LiquidThreads) having two toolbars instead of one. This was quickly fixed by Bartosz and Ed.
Finally, I would advertise a presentation about MediaWiki best practices I gave in the Fantastic MediaWikis track. It summarizes a few of the best practices I have come up during my experience maintaining translatewiki.net and many other MediaWiki sites. It has tips about deployment, job queue configuration and short main page URLs and slides are available.
As a small bonus, I finally updated my blog to use https, so that I could write and that you could read this post safely knowing that nobody else but me could have put all the bad puns in the post.


















{kind=link}