I told my friend Nemo that I have been reading the recently published Open Advice book and he basically forced me to write a review about it. This isn’t really a review, but instead something the book made me think. When I started reading the book I expected to get some simple tips on how I could do things better or on new things I could do. Well, I didn’t get those, but I got something else.
The book consists of many short stories of open source from different starting points – each story is written by a different author. It was nice to notice that among the writers there were many who I’ve met or at least whose name and work I knew. Most of the stories didn’t tell anything new to me, and the section about translation was annoyingly short of content. The book is worth reading, especially since each story is short, which makes it easy to read.
When I read what follows in Markus Krötzsch’s Out of the lab, into the Wild, I started thinking.
When a certain density of users is reached, support starts to happen from user to user. This is always a magical moment for a project, and a sure sign that it is on a good path.
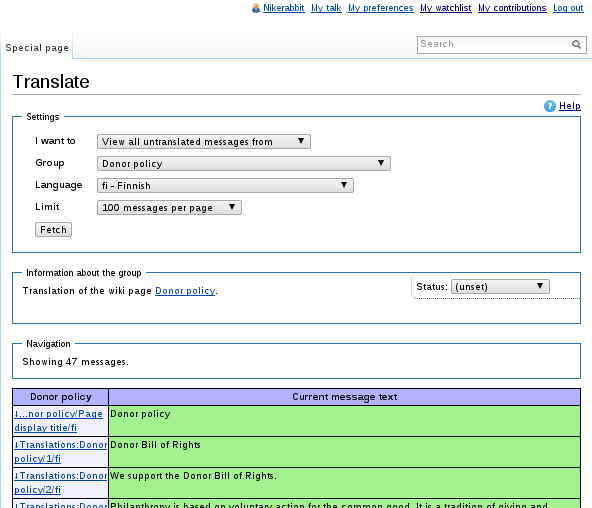
I have been developing the Translate extension (and by extension translatewiki.net too) for many years now, but apart from seeing it being used more and more, I haven’t really stopped to think what it means for a software project to grow up and be successful. So I made up some milestones:
- You write something for yourself
- Other people find it useful and start using it
- The users of your software are providing peer to peer help
- Other developers are able take over maintenance and development of the software
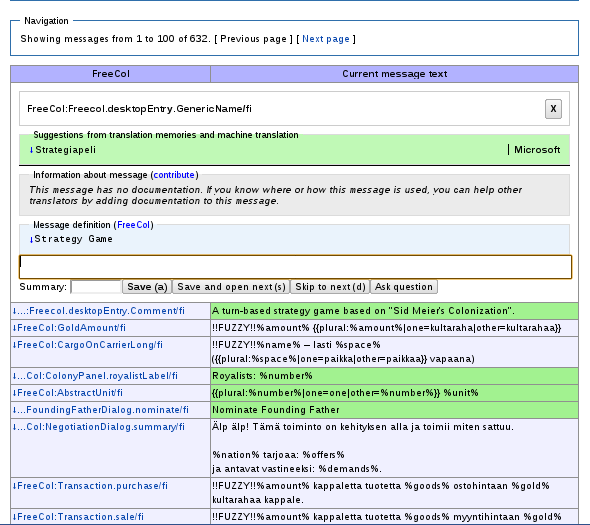
Now we have something we can measure. I started writing Translate over five years ago. Some years later there were already tens of translators using it. This year the Translate extension is used in many Wikimedia projects as well as in KDE UserBase in addition to translatewiki.net. Lots of new people need to learn how to use the Translate extension from a management point of view, and more and more often they get an answer not from me but from someone else or by reading the documentation.
So what about step 4? Until very recently Translate has been my world and my world only apart from some patch contributions. But I have now taken it as my personal goal to change this. And what a lucky person I am! The Wikimedia Localisation Team – which I am member of – has the development of Translate extension as one of their major goals. Even better, we are an agile team, which means that each and every developer of the team should be able to do any development task in the team. To achieve this we divide tasks among team members so that nobody works only on their own favourite project. In addition we are explicitly reserving time for knowledge transfer, which happens through code review, proofreading the documentation one of us has written, explicit sessions where a team member covers a topic they know well and pair programming. This has already been going on for some months and it is not going to stop.
In addition to schooling the other developers in our team, I also plan to keep expanding the documentation, adding more tutorials and organizing tasks suitable for new developers, so that it is easy for interested volunteer developers to start contributing to Translate. Because in the end knowledge is useless if the developer has no reason to develop, and the best reason to develop is to scratch your own itch. I believe those developers are to be found among the users of the Translate extension who have a slightly different and new use case which needs development work.
I haven’t yet finished my plans on the fifth step (world domination), so stay tuned for coming blog posts.