The message index is a crucial component of Translate, so I made an experiment by implementing a trie store for the message index to optimize it. The short story is that I could not get it fast enough for practical use easily. Continue for full story.
Pet projects

A tree in Helsinki (October) showing something tries can’t produce: wonderful fall colours (ruska in Finnish)
For context, in our development team each developer has time for experimentation, outside of the planned development sprint tasks. During that time the developer can try out new technologies, fix issues that are important to them personally or just do something fun and interesting. We call these pet projects and they let us do some cool things.
For example, the insertables I described in my previous blog post are something I did as a pet project. Insertables were actually part of the original translation UX (TUX) design specifications, but they were not implemented because of other priorities. I decided to implement them because users (not managers) were asking for it. I wasn’t convinced initially, but when I saw users translating with tablets I changed my mind. Insertables were a good pet project because they were relatively small and fun a thing to do.
This is all I have to say about pet projects – the non technical readers can skip the rest of this post, where I go into the details of this pet project.
Message index
I probably have introduced the message index in my earlier posts, but let me do it again quickly. I’ll use an example for this. Let’s assume we have a small software called Greeter. It has a localisation file like this:
# l10n/en/greetings.properties greeting.noon = Good day greeting.morning = Good morning greeting.evening = Good evening greeting.night = Good night
When this kind of file is set up with the Translate extension (for instance in translatewiki.net), each string is stored as a wiki page. Each translation is a separate page, too.
translatewiki.net/wiki/Greeter:greeting.noon/en -> “Good day”
translatewiki.net/wiki/Greeter:greeting.noon/fi -> “Hyvää päivää”
The bolded parts are called page titles in MediaWiki. The message index can be defined simply as a map from the page title of each known message (without the language code) to the message group it belongs to. If we printed it out it would look something like this:
1244:greeting-noon => [greeter]
1244:greeting-morning => [greeter]
1244:greeting-evening => [greeter]
1244:greeting-night => [greeter]
So, every time someone adds a new message for translation, we need to update the message index. Every time someone makes a translation, we need to query the message index. The user is waiting, so both of these actions need to be fast, while using a reasonable amount of memory.
Implementations problems
When we get to the order of 50 000 or even more known messages, creation and accessing of the message index starts to get slow in PHP, even though it’s basically just a lot of strings, and string processing should be fast, right? Not so in PHP, where holding the message index as an array of arrays takes tens of megabytes in memory. An array in php is kind of a mix of hashtable and linked list. It uses more memory for extra features and versatility.. In the case of message index we would gladly like to trade some features for reduced memory usage.
There are many aspects in message index optimization, but so far I haven’t found a solution without downsides. If the whole index was small enough, it could be kept in memory, making things faster; but currently it can only be stored in various kinds of databases, that allow querying the index one title at the time.
Currently at translatewiki.net we are using CDB files, which are immutable databases stored on a file on the file system. This is okay for our use case: the index is accessed from disk; only when the data changes, you have to build the whole thing from scratch and you have to worry about memory usage and speed. The current problem we have with this approach is that it takes a lot of memory to recreate it, and the few second running time is on the borderline of acceptable speed for having user to wait for it. There isn’t too much room for growth.
To reach the current state, I’ve tried using references to store the group names to avoid repeating them and storing the resulting array in a serialized file. I’ve tried storing the whole structure in a database table, which works well to certain amount of messages. This time I’m going to try something else. The idea is to save space by considering that the message keys share a lot of substrings, for instance the messages of a MediaWiki extension having all keys prefixed with the extension’s name. I decided to use tree structures to experiment.
Trees and tries
Disclaimer: I haven’t studied algorithms in depth so I’m just trying to apply what I know.
We can represent all the relationships between message names and their groups as a set of mostly similar strings which may share common prefixes. I could have used a tree, but I decided to use a trie. A trie is a tree where consecutive nodes which only have one child are merged together. Here is an example of how the message index above would look like in a trie (first image), compared to the full tree (second image). As you can see, the trie is more compact compared to the tree because it has less nodes and branches. The trie is also more compact than an array as the common prefixes can be stored only once and we are not using any hashes which are used in arrays. Click for full size.
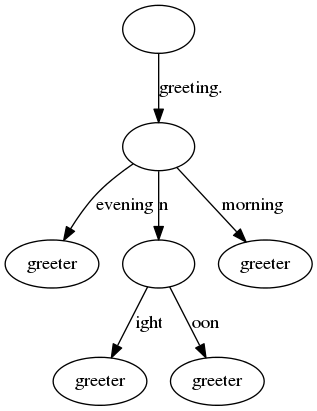
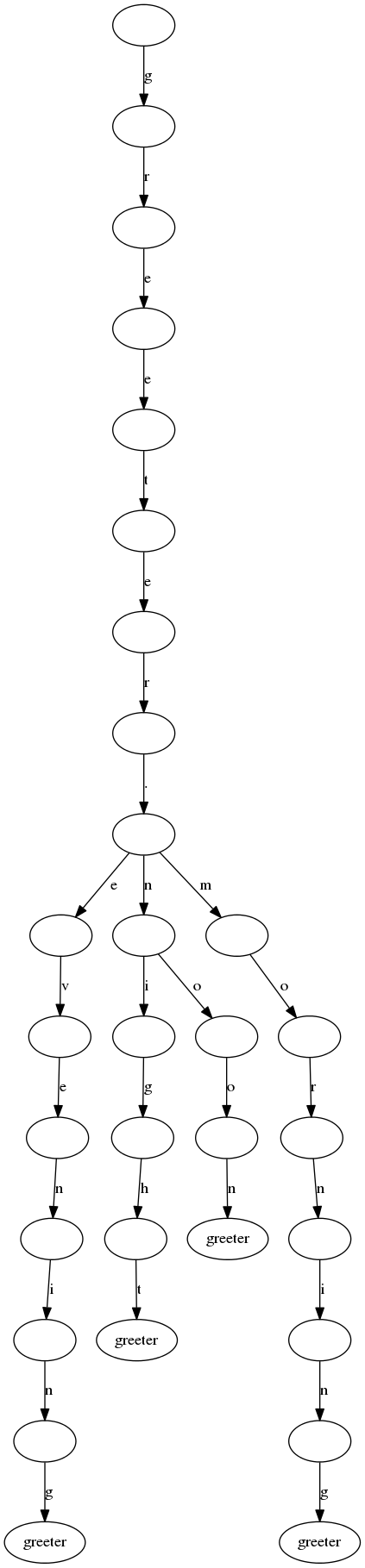
To create a message index using tries, I started by googling if there are any algorithms already implemented in PHP for constructing tries. I could not find any, so I just converted into PHP a Python script (which was likely converted from Java). Then I implemented a custom binary format that could be stored in a file and a custom lookup that would use the data loaded from the file into a memory.
I tried many options for optimizing the creation of the trie while minimizing the storage consumption.
One of the curious things was that, when inserting a new string to the trie, it is faster to loop over all the current children of the node comparing the first letter of the child against the first letter of the string we are inserting, rather than to use binary search to find the correct insertion point. The latter would mean keeping the list of children sorted and doing less comparisons by using binary search when doing lookups and insertions. I assume this is because inserting at the end of the array is fast, but inserting in the middle of the array (to keep it sorted) is slow because (my guess) PHP either recreates the array or updating the linked list pointers is slow for some other reason.
For the storage format I tried various kinds of indexes of strings to store the substrings only once, but all the pointers to the strings and child nodes also take a lot of space (4 bytes per pointer, where 4 bytes can also store four characters assuming ascii keys). I’m sure more space savings could be gained by experimenting with alignments so that smaller pointers could be used. Maybe it would be possible borrow some of the algorithms designed to optimize finite state automata – I believe those are much better than what I can do on my own.
Here are some numbers (approximate because I ran out of time to measure properly) on how it compares to the CDB message index solution:
| Property | CDB | Trie |
|---|---|---|
| Size on disk | 6 MiB | 1.5 MiB (0.5 compressed with gzip) |
| Time to create | 1 second | 7 seconds |
For now I declare this pet project as something that cannot be used. Maybe some day I will get back to it and try make it good enough for real use, but now I already have other interesting pet projects in my mind. If I get suggestions from you how to reach practical solutions, I will of course try them out sooner. I just want to mention that there a many things that could still be explored: QuickHash, constant hash database or finding ways to store group information so that message index is not needed at all.
Pingback: Performance is a feature « It rains like a saavi