It has been a busy spring: I have yet to blog about Translate UX and Universal Language Selector projects, which have been my main efforts.
But now something different. In this field you can never stop learning. So I was very pleased when my boss let me participate in a week-long course, where Francis Tyers and Tommi Pirinen taught how to do machine translation with Apertium. Report of the course follows.
From translation memory to machine translation
Before going to the details about the course, I want to share my thoughts about what is the relation between the different translation memory and machine translations techniques we are using to help translators. The three different techniques are:
- Crude translation memory: for example the TTMServer of Translate
- Statistical machine translation: for example Google Translate or Microsoft Translator
- Rule-based machine translation: for example Apertium
In the figure below, I have used two properties to compare them.
- On x-axis is the amount of information that is extracted from the stored data. Here the stored data is usually a corpus of aligned* translations in two or more languages.
- On y-axis is the amount of external knowledge used by the system. This data is usually dictionaries, rules how words inflect and rules about grammar–or even how to split text into sentences and words.
* Aligned means that the system knows which parts of the text correspond to each other in the translations. Alignment can be at paragraph level, sentence level or even smaller parts of the text.
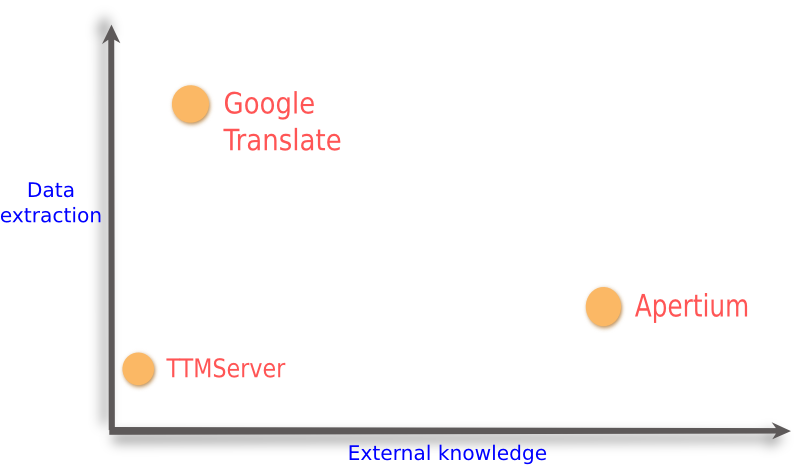
A very crude implementation just stores an existing translation and can retrieve it if the very same text is translated again.
TTMServer is a little more sophisticated: it splits the translation into paragraph-sized chunks, and it can retrieve the existing translation even if the new text does not match the old text exactly. This system uses only a little information about the data. Even if all the words exist in it, translated as part of different units (strings), the system still cannot provide any kind of translation. Internally, TTMServer uses some external knowledge on how to split up text into words, in order to speed up translation retrieval.
Statistical machine translation at simplest is just a translation memory which extracts more information about the stored translation data. It gathers a huge database about which words usually occur as translation of the words in the source language. Usually it also stores the context so that in the sentence “walking along the river bank” the term “bank” is not interpreted as a building. Most sophisticated systems can also include knowledge about inflection and grammar to filter out invalid interpretations, or even fix grammatically incorrect forms.
On the right hand side of the figure we have rule-based machine translation systems like Apertium. These systems mainly rely on language dependent information supplied by the maker of the system: bilingual dictionaries, inflection and syntax rules are needed for them to function. Unlike the preceding ones, such systems are always language specific. Creating a machine translation needs a linguist for each language in the system.
Still, even these systems can benefit from statistical methods. While they do not store translation data itself, such data can be analysed and used as input to find the correct way to read ambiguous sentences, or the most common translation of a word in the given context among some alternatives.
The ultimate solution for machine translation is most likely a combination of rules and information extracted from a huge translation corpora.
The course
To create a machine translation system with Apertium, you need to choose a source and target language. I built a system to translate from Kven to Finnish. Kven is very close to Finnish, so it was quite easy to do even though I do not know much Kven. Each student was provided skeleton files and a story in the source language, also translated to the target language by a human translator.
We started by adding words in order of frequency to the lexicon. Lexicon defines part of speech and the inflection paradigms of the words. The paradigms are used to analyze the word forms, and also for generation when translating in the opposite direction. Then we added phonological rules. For example Finnish has a vowel harmony. Because of that, many word endings (cases) have two forms, depending on the word – for example koirassa (in the dog), but hiiressä (in the mouse).
As a third step, we created a bilingual dictionary in a form that is suitable for machines (read: XML). At this point we started seeing some words in the target language. Of course we also had to add the lexicon for the target language, if nobody else had done it already.
Finally we started adding rules.
We added rules to disambiguate sentences with multiple readings. For example, in the sentence “The door is open” we added a rule that open is an adjective rather than a verb, because the sentence already has a verb.
We added rules to convert the grammar. For example Finnish cases are usually replaced with prepositions in English. We might also need to add words: “sataa” needs an explicit subject in English, “it rains”.
At the end we compared the translation produced by our system with the translation made by the human translator. We briefly considered two ways to evaluate the quality of the translation.
First, we can use something like edit distance for words (instead of characters) to count how many insertion, deletions or substitutions are needed to change the machine translation to human translation. Otherwise, we can count how many words the human translator needs to change when copy editing the machine translation.
Machine translation systems start to be useful when you need to fix only one word out of six or more words in the translation.
The future
A little while ago Erik asked how the Wikimedia Foundation could support machine translation, which is now mostly in hands of big commercial entities (though the European Union is also building something) and needs an open source alternative.
We do not have lot of translation corpora like Google. We do have lots of text in different languages, but it is not the same content in all languages and it’s not aligned. Exceptions are translatewiki.net and other places where translations are done with the Translate extension. As a side note I think that translatewiki.net contains one of the most multilingual parallel translation corpora under a free license.
Given that we have lots of people in the Wikimedia movement who are multilingual and interested in languages, I think we should cooperate with an existing open source machine translation system (like Apertium) in a way that allows our users to enhance that system. Doing more translations increases the data stored in a translation memory making it more useful. In a similar fashion, doing more translations with machine translation system should make it better.
Apertium has already been in use on the Nynorsk Wikipedia. Bokmål and nynorsk are closely related languages: the kind of situation where Apertium excels.
One thing I have been thinking is that, now that the Wikimedia Language Engineering team is planning to build tools to help translate Wikipedia articles into other languages, we could closely integrate it with Apertium. We could provide an easy way for translators to add missing words and report unintelligible sentences.
I don’t expect most of our translators to actually write and correct rules, so someone should manage that on Apertium side. But at least word collection could be mostly automated; I bet someone has tried and will try to use Wiktionary data too.
As a first step, Wikimedia Foundation could set up their own Apertium instance as a web service for our needs (existing instances are too unstable). The translate extension, for example, can query such a web service to provide translation suggestions.
The slides of the course are available at http://apertium.svn.sourceforge.net/viewvc/apertium/branches/courses/helsinki_2013/slides/