In case you haven’t already noticed, I like working on performance issues and performance improvements. Performance is a thing where you have to consider the whole stack: the speed of the server, efficient algorithms, server side caching, bandwidth and latency, client side caching and client side code. Here is a short recap of what has been done for translatewiki.net lately and some ideas for the future.
Recent improvements
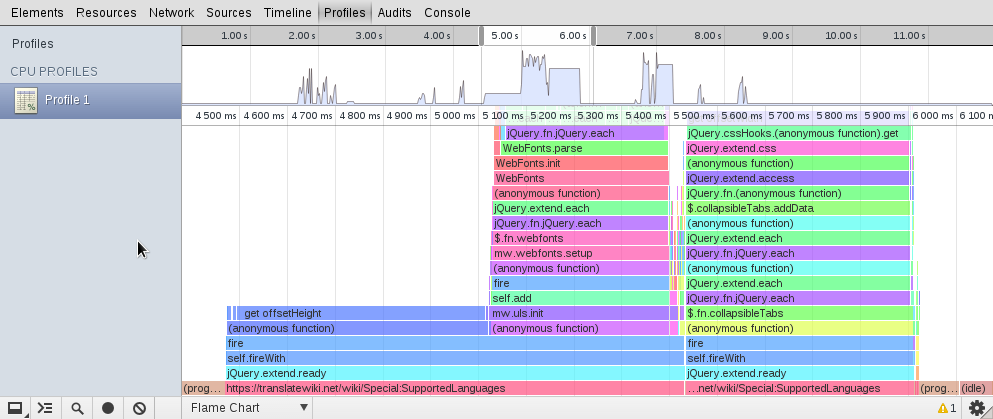
Chrome 29 (or later release) has added a helpful visualization for profiling data. In this image the speed of ULS JavaScript code is evaluated on a fonts heavy page. Comparing to the collapsible tabs feature, it is doing okay.
Server level. A month ago translatewiki.net got a new server with more memory and faster processors. The main benefit is that we can handle more simultaneous users and background tasks without them slowing each other down. At the same time, we upgraded many of the programs to newer versions. The switch from MySQL to MariaDB is the most important one. We haven’t tested it for our use case, but the Wikimedia Foundation found that the switch had overall positive impact on performance.
Web server level. In the beginning of November I configured our nginx web server to enable support for the SPDY protocol. This should greatly reduce latency when browsing over HTTPS. We are considering to switch to HTTPS by default. While tweaking nginx, I also fixed a few settings that relate on the compression and expiry times of JavaScript, SVG images and font assets when delivered to users. I used AWStats to see if our daily bandwidth usage decreased. It has not decreased significantly, but there is a lot of variation between days that make interpreting the data difficult. PageSpeed was used to ensure that caching headers are optimal and WebPagetest to confirm that pages load faster on different browsers in different places.
Application level. The Language Engineering team has recently worked a lot on the performance of Universal Language Selector (ULS) and Translate extensions. A short summary of the things which were done:
- Reduce the amount of JavaScript and CSS delivered to the browser.
- Delay the loading of JavaScript and CSS as much as possible (for example till the user opens ULS).
- Optimize JPG, SVG and PNG images to the last byte with tools like jpegoptim, optipng.
- Optimize the JavaScript to avoid slow actions (for example repaint events and dom changes). We used Chrome’s JavaScript profiler as well as the experimental tool “show potential scroll bottlenecks” to identify issues and confirm the fixes (thanks Ori).
In addition I fixed a major performance issue in one of the Translate API modules by replacing an inefficient algorithm with a faster one. While investigating that issue, I also noticed that ReplacementArray-strtr was taking 20% or so of MediaWiki run time. There is a less known PHP module FastStringSearch, which was not installed on the new server. Installing that module made a big difference on the MediaWiki profiling table: ReplacementArray-fss is now taking only about 0.20% of MediaWiki run time.
Finally, a thing called module local storage was enabled on Wikimedia wikis few days ago (the title of this post was taken from that discussion). As is usual for translatewiki.net, we were already beta testing that feature a few weeks before it went live on Wikimedia wikis.
Future plans
It is hard to plan the future for further performance improvements, as the bottlenecks and the places where you can make the most difference for the least effort change constantly, together with the technology and your content. I believe that HHVM, a JIT PHP virtual machine, is likely to be the next step which will make a significant difference. It is however not a straightforward thing to jump from a normal PHP intepreter to HHVM, so I will be keeping a close eye on how my colleagues at the Wikimedia Foundation are progressing with the adoption of HHVM.
Another relatively small thing on the horizon is better compression of inline SVG images in CSS style sheets, by avoiding unnecessary base64 encoding. Or something else might happen even before it.
Finally, I’d like to highlight that while the application-level improvements automatically benefit third party users, there really isn’t any coherent documentation on how to improve performance of a MediaWiki site at all levels. Configuring localisation cache, nginx and/or Varnish, tweaking MySQL or MariaDB and installing Memcached or Redis should be part of any capable sysadmin’s skills; but even just tailoring them for MediaWiki, let alone knowing which PHP modules to install, is likely not known by many. For example, I wouldn’t be surprised if there were very few or even no sites using the FastStringSearch module outside of Wikimedia and translatewiki.net.