Translatewiki.net features a good user experience for non-technical translators. A crucial or even critical component is signing up. An unrelated data collection for my PhD studies inspired me to get some data on the translatewiki.net user registration process. I will present the results below.
History
At translatewiki.net the process of becoming an approved translator has been, arguably, complicated in some periods.
In the early days of the wiki, permissions were not clearly separated: hundreds users were just given the full set of permissions to edit the MediaWiki namespace and translate that way.
Later, we required people to go through hoops of various kind after registering to be approved as translators. They had to create a user page with certain elements and post a request on a separate page and they would not get notifications when they were approved unless they tweaked their preferences.
At some point, we started using the LiquidThreads extension: now the users could get notifications when approved, at least in theory. That brought its own set of issues though: many people thought that the LiquidThreads search box on the requests page was the place where to write the title of their request. After entering a title, they ended up in a search results page, which was a dead end. This usability issue was so annoying and common that I completely removed the search field from LiquidThreads.
In early 2010 we implemented a special page wizard (FirstSteps) to guide users though the process. For years, this has allowed new users to get approved, and start translating, in few clicks and a handful hours after registering.
In late 2013 we enabled the new main page containing a sign-up form. Using that form, translators can create an account in a sandbox environment. Accounts created this way are normal user accounts except that they can only make example translations to get a feel of the system. Example translations give site administrators some hints on whether to approve or reject the request and approve the user as a translator.
Data collection
The data we have is not ideal.
- For example, it is impossible to say what’s our conversion rate from users visiting the main page to actual translators.
- A lot of noise is added by spam bots which create user accounts, even though we have a CAPTCHA.
- When we go far back in the history, the data gets unreliable or completely missing.
- We only have dates for account created after 2006 or so.
- The log entry format for user permissions has changed multiple times, so the promotion times are missing or even incorrect for many entries until a few years back.
The data collection was made with two scripts I wrote for this purpose. The first script produces a tab separated file (tsv) containing all accounts which have been created. Each line has the following fields:
- username,
- time of account creation,
- number of edits,
- whether the user was approved as translator,
- time of approval and
- whether they used the regular sign-up process or the sandbox.
Some of the fields may be empty because the script was unable to find the data. User accounts for which we do not have account creation time are not listed. I chose not to try some methods which can be used to approximate the account creation time, because the data in that much past is too unreliable to be useful.
The first script takes a couple of minutes to run at translatewiki.net, so I split further processing to a separate script to avoid doing the slow data fetching many times. The second script calculates a few additional values like average and median time for approval and aggregates the data per month.
The data also includes translators who signed up through the sandbox, but got rejected: this information is important for approval rate calculation. For them, we do not know the exact registration date, but we use the time they were rejected instead. This has a small impact on monthly numbers, if a translator registers in one month and gets rejected in a later month. If the script is run again later, numbers for previous months might be somewhat different. For approval times there is no such issue.
Results
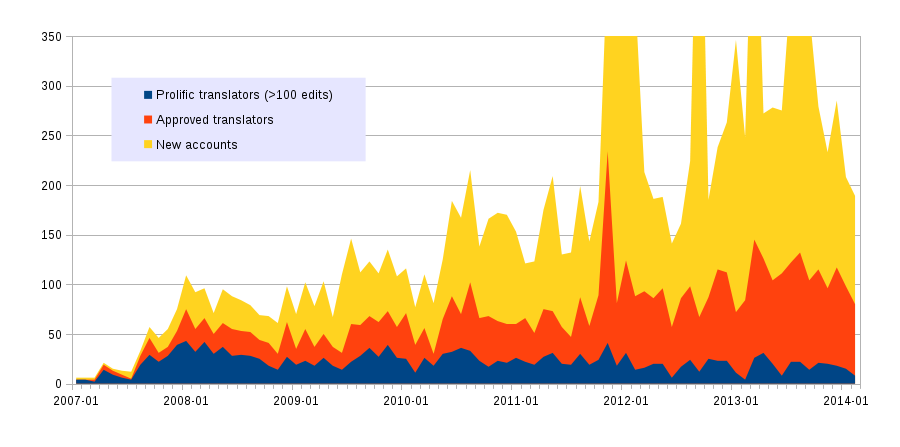
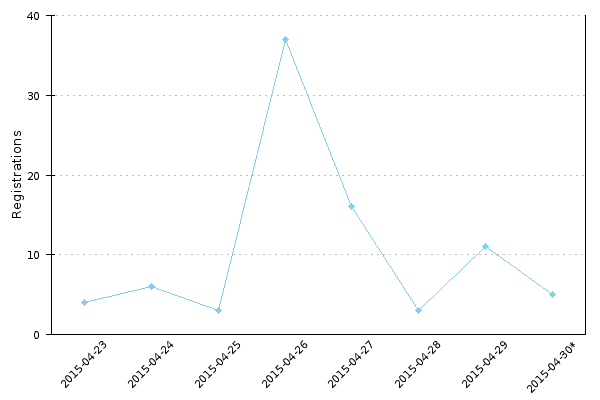
Image 1: Account creations and approved translators at translatewiki.net
Image 1 displays all account creations at translatewiki.net as described above, simply grouped by their month of account creation.
We can see that approval rate has gone down over time. I assume this is caused by spam bot accounts. We did not exclude them hence we cannot tell whether the approval rate has gone up or down for human users.
We can also see that the number of approved translators who later turn out to be prolific translators has stayed pretty much constant each month. A prolific translator is an approved translator who has made at least 100 edits. The edits can be from any point of time, the script is just looking at current edit count so the graph above doesn’t say anything about wiki activity at any point in time.
There is an inherent bias towards old users for two reasons. First, at the beginning translators were basically invited to a new tool from existing methods they used, so they were likely to continue to translate with the new tool. Second, new users have had less time to reach 100 edits. On the other hand, we can see that a dozen translators even in the past few months have already made over 100 edits.
I have collected some important events below, which I will then compare against the chart.
- 2009: Translation rallies in August and December.
- 2010-02: The special page to assist in filing translator requests was enabled.
- 2010-04: We created a new (now old) main page.
- 2010-10: Translation rally.
- 2011: Translation rallies in April, September and December.
- 2012: Translation rallies in August and December.
- 2013-12: The sandbox sign-up process was enabled.
There is an increase in account creations and approved translators a few months after the assisting special page was enabled. The explanation of this is likely to be the new main page which had a big green button to access the special page. The September translation rally in 2011 seems to be very successful in requiting new translators, but also the other rallies are visible in the chart.
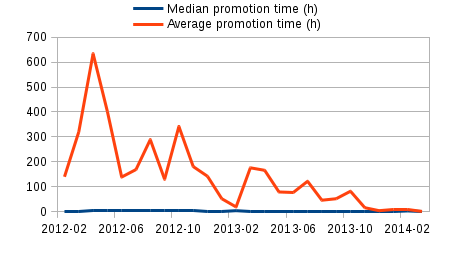
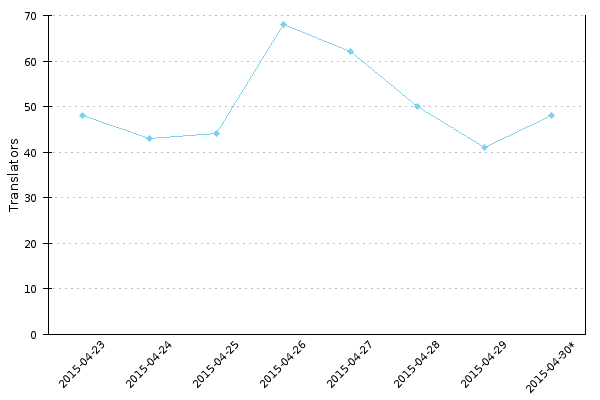
Image 2: How long it takes for account creation to be approved.
The second image shows how long it takes from the account creation for a site administrator to approve the request. Before sandbox, users had to submit a request to become translators on their own: the time for them to do so is out of control of the site administrators. With sandbox, that is much less the case, as users get either approved or rejected in a couple of days. Let me give an overview of how the sandbox works.
All users in the sandbox are listed on a special page together with the sandbox translations they have made. The administrators can then approve or reject the users. Administrators usually wait until the user has made a handful translations. Administrators can also send email reminders for the users to make more translations. If translators do not provide translations within some time, or the translations are very bad, they will get rejected. Otherwise they will be approved and can immediately start using the full translation interface.
We can see that the median approval time is just a couple of hours! The average time varies wildly though. I am not completely sure why, but I have two guesses.
First, some very old user accounts have reactivated after being dormant for months or years and have finally requested translator rights. Even one of these can skew the average significantly. On a quick inspection of the data, this seems plausible.
Second, originally we made all translators site administrators. At some point, we introduced the translator user group, and existing translators have gradually been getting this new permission as they returned to the site. The script only counts the time when they were added to the translator group.
Alternatively, the script may have a bug and return wrong times. However, that should not be the case for recent years because the log format has been stable for a while. In any case, the averages are so big as to be useless before the year 2012, so I completely left them out of the graph.
The sandbox has been in use only for a few months. For January and February 2014, the approval rate has been slightly over 50%. If a significant portion of rejected users are not spam bots, there might be a reason for concern.
Suggested action points
- Store the original account creation date and “sandbox edit count” for rejected users.
- Investigate the high rejection rate. We can ask the site administrator why about a half of the new users are rejected. Perhaps we can also have “mark as spam” action to get insight whether we get a lot of spam. Event logging could also be used, to get more insight on the points of the process where users get stuck.
Source material
Scripts are in Gerrit. Version ‘2’ of the scripts was used for this blog post. Processed data is in a LibreOffice spreadsheet. Original and updated data is available on request, please email me.