My progress on implementing nice statistics has been an on-off trip. Both MediaWiki and FreeCol are going to make releases soon. And then there is all kinds of bugs here and there I feel obligated to fix. During the weekend I managed to fix a very bad memory leak where one of our scripts was using all our memory from the server, compared to quite stable 30M after the fix. I really want to thank milian from #geshi for the help using xdebug and his nice tools to identify the cause.
Gettext and Xliff: Nothing much here. Still haven’t tested msgmerge, so it is to be seen how well it works.
Other features: Special page alias translation got a really big boom. Suddenly the number of supported extensions has grown to 23, and we have already “produced” hundreds of translations in many languages. Message formatting checks got little improvements, and now that the leak is fixed, we can update those regularly too.
So let’s go ahead to the stuff I was meant to do: Stats. Thanks to a friend who suggested using PHPlot, I have managed to make pretty good progress on this anyway with all the other stuff going on. I think I’m going to explain my progress by using few examples and eye candy. Click the images to show full size versions if they are scaled.
First we have a graph of showing the number of translation edits per day in Betawiki.
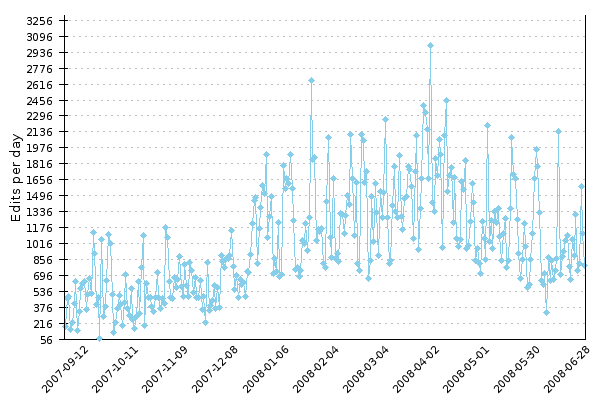
It is also possible to compare projects:
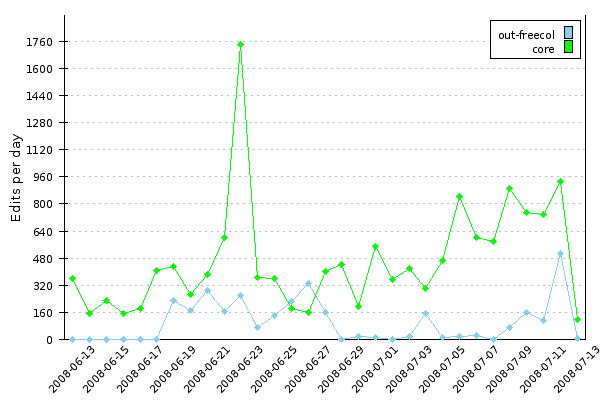
And then we have graphs in our portals:
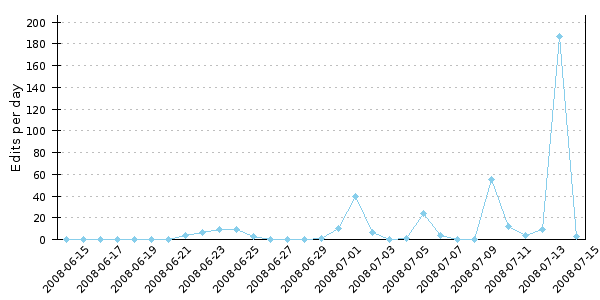
Or if you want to compare how your worst (best?) rival is doing much better than your language:
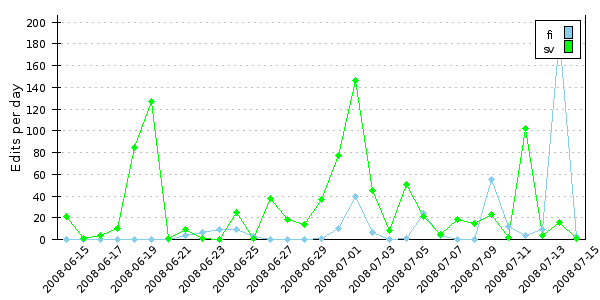
Or do it only for one project:
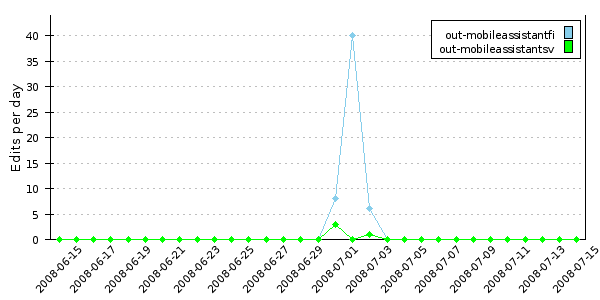
We also have graphs in our project pages.
As you can see, the labels could use some polishing. There is no GUI for generating these, but it is easy if one knows the configuration parameters. It is possible to include them in pages with the special page inclusion syntax: {{Special:TranslationStats/language=xx;days=nn;group=id}} The size can also be changed with width and height parameters.
Every graph is visually about the same. I kind of like it, but YMMV. If this feature turns out to be very popular, I have to figure out how to do more aggressive caching. The data is is fetched from Betawiki recent changes table. It means that external changes are not counted—one more reason to use Betawiki.